- SOLUTIONS
- PRODUCTS
- SERVICES
- PARTNERS
- RESOURCES
Is RAID Dead?- Part 3

Is RAID Dead?- Part 2

The World’s Fastest Storage Cluster
Is RAID Dead?- Part 3

Limitations of RAID & The Rise of Software Defined Storage
Scale-Up vs Scale-Out
In a legacy RAID-based storage system, when more storage capacity is needed, we can add more drives to a node. A node comprises of a controller (made up of CPUs, memory, network interfaces, RAID controllers, etc) connected to one or more chassis of drive bays, where the drives are held. The maximum capacity of the node is reached when all drive bays are occupied or when the controller can no longer support additional drives, because physical performance limit is reached. When you add a new node for additional capacity, it is a new storage system. It is not an extended system of the original storage. You end up with silos of storage.
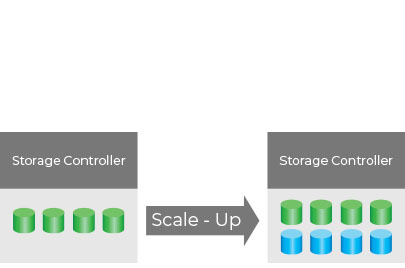
This is an example of a scale-up system, where we add additional resources to the system to increase the performance and capacity. In a scale-up system, we will reach a physical limit where we can no longer add any more resources.
In an SDS system, when more storage capacity is needed, we add more nodes to the cluster. Each node handle one or more drives. With each node added, the capacity and performance linearly increases, and the new capacity appears as an extension to the system.
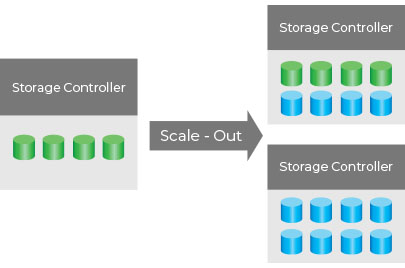
This is an example of a scale-out system. In a software-defined scale-out system, there is almost no limit on how much capacity can be handled. Each node that is added into the cluster creates more opportunities for parallelism, and hence increases performance.
When A Drive Fails
Drives Are Getting Bigger; Accelerated by Advances in Technology.
Backup!
It is best practice to do a backup of your data in your storage arrays before you attempt to replace a failed drive in a RAID 5 or 6 system, or in any RAID system. Any human error introduced in the drive replacement process can mean a total data wipeout. Or another unexpected drive failure while rebuilding in progress can mean the same thing. Therefore, a backup is always recommended. Doing backup means adding more time to the completion of data rebuilding. Your risks mount. SDS system commence the data rebuilding automatically. Backup is not necessary. No human involved means no human errors.
Cost and Performance
Enterprises demand that storage systems be of high reliability and performance. To meet this requirement, legacy RAID-based storage systems use expensive enterprise-grade, dual-port SAS drives, spinning upwards to 15K RPMs. Dual-port allows the HDDs to be connected to redundant RAID controllers. To increase performance, each drive capacity is not maximized. More HDDs means more IOPs (hence more performance), and lower data rebuild times.
Together with proprietary hardware systems and software, a RAID-based system is very expensive.
SDS system is designed around failure in mind. It leverages on inexpensive, commodity server systems, uses low-cost (but still enterprise grade) SATA drives. With self-healing and automatic data rebuilds around failures, expensive dual-port SAS HDDs then become unnecessary. As a scale-out architecture, with lots of small nodes controlling lots of HDDs, it is capable of delivering performance rivalling and exceeding RAID-based systems.
Growth of Data
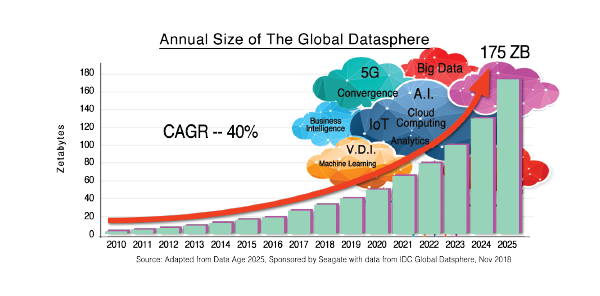
The amount of data generated and stored has grown by leaps and bounds. To many governments and large enterprises, data is the lifeblood. Better decisions can be made with more and better quality data.
Storing these data need not be expensive anymore with SDS.
By 2025, more than a quarter of the data created in the global Datasphere will be in real time.
Is RAID Dead?
RELATED ARTICLES
Is RAID Dead? Part 1
Is RAID Dead? Part 2
Is RAID Dead? Part 3