- SOLUTIONS
- PRODUCTS
- SERVICES
- PARTNERS
- RESOURCES
The World’s Fastest Storage Cluster

Is RAID Dead?- Part 3

Free Network Design Support

The World’s Fastest Storage Cluster
Every high-performance application, such as high-frequency transaction processing, time-series database, high-performance database, AI/Machine-Learning, data-lakes/data analytics, requires data to be read and stored in a very fast storage infrastructure. Current hard-drive performance is insufficient for such applications.
Today’s fastest storage medium is NVMe (Non-Volatile Memory Express). It is the successor of SSD (Solid State Drive). SSD is designed on top of the interface of hard-drives, ie SATA, so that it can be a convenient replacement of hard-drives whenever faster storage is needed. SATA controllers, in turn is connected to PCIe, the standard data exchange bus between the CPU and other peripherals devices. The problem, however, is that SSD is capable of transferring data faster than what SATA is capable of, hence a new interface is needed. NVMe is designed to overcome the speed limitations of SATA, by bypassing SATA and directly interface storage into the PCIe bus. The latest implementation is PCIe 5, capable of 4GB/s per lane (PCIe 4 is 2GB/s per lane). Peripheral devices based on PCIe 5 is rare today, so most peripherals are connected using PCIe 4. High-speed peripheral devices, eg GPUs, typically uses 4, or 8 or even 16 lanes, to achieve high-speed data-transfers.
High-Performance Storage Cluster
A high-performance storage cluster is typically built around standard x86 servers, connected to an array of NVMe drives. Each server node is in-turn connected over a high-speed fabric, eg Infiniband or in most cases over high-speed 100G Ethernet. Using software based on Software-Defined Storage (SDS) principles, a scale-out storage infrastructure is made possible. Each node is capable of achieving up to 3M IOPs, an impressive number when compared to hard-drives.
In our quest to push performance even higher, the x86 CPU server architecture becomes the bottleneck in performance. Features such as compression/decompression, encryption, erasure coding, which are common in SDS, are compute intensive tasks. The x86 CPUs becomes the bottleneck, slowing down IOPs when such features are enabled.
A new approach is needed to break the performance barrier. A DPU-based NVMe storage from Fungible is now available, which is capable of delivering up to 13M IOPs and 65GB/s throughput from a single storage node.
What is a DPU And Why Does It Matter?
A DPU, also known as a Data Processing Unit, is a souped-up Ethernet NIC card, with an optimized packet processing engine combined with 16 cores of ARM processors (implementations using MIPs are also available). It is designed to replace an Ethernet NIC card, and installed in a server. DPU is capable of handling packet processing at line rates, and excel at compute intensive tasks, exactly like compression/decompression, encryption, erasure coding, the full TCP stack, and other networking functions. Therefore, such tasks can be off-loaded from the server CPU onto the DPU, thereby freeing up resources, so that the CPU is now dedicated to run real workloads. The DPU has it’s own on-board Operating System, typically Linux Ubuntu, so that services such as network firewall, routing, etc can be installed.
The use cases of DPU is now expanded by Fungible to make available the world’s fastest storage cluster. Instead of having an x86 server controlling an array of NVMes, a high-performance Fungible DPU connects directly to arrays of NVMes over PCIe. Since a DPU can perform packet processing at line rates, storage features such as compression/decompression, encryption and erasure coding can be achieved at the highest possible speed.
Introducing Fungible’s FSC 1600 Storage Cluster
Fungible’s FSC 1600 is a pure DPU-based storage array. It disaggregates storage, enables independent scaling of compute and storage, thereby increasing utilization and agility, and reducing cost and complexity.
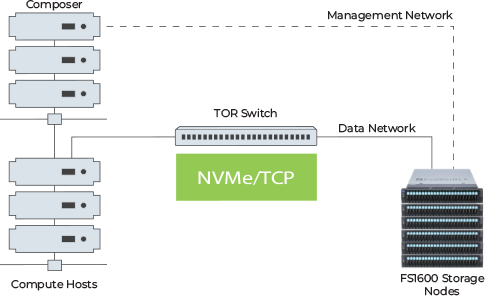
Compared to typical x86 based storage nodes, FSC 1600 delivers the following benefits :

- Best-in-class Performance : At 13M IOPs per node, it performs at least 4 times faster than x86 based NVMe storage arrays, and it does so even with advanced features enabled that slows down typical x86 servers.
- Unrivaled Economics : Erasure coding that can be done across nodes, and compression provide 2X effective capacity over replicated data protection schemes.
- Volume-Based Data Services : Compression, erasure coding, QoS, encryption at full line rate and configurable per-volume.
- Power & Cooling Efficiency : At 850W peak fully loaded with NVMes, it is the industry’s most power-efficient storage. A fully loaded x86 based platform will consume about 2000W. And less heat generated means less cooling. This means you save money on electricity and cooling.
- Scale-out Architecture : Storage capacity scale linearly with new cluster nodes, independently of compute.
- No-Compromise Security : Immutable root of trust, line rate per-volume encryption, and volume-based QoS.